






优化问题等同于最小化或最大化某个函数 ,如果
不是取整个向量空间,则称为有约束的优化问题,约束条件通常通过一系列等式和不等式表示
深度学习中最小化损失函数就是一个典型的优化问题,即找到一组参数 使得损失函数
达到最小值。
在大多数深度学习应用中,因为模型是人为定义的,我们通常处理无约束的优化问题,意味着我们尝试在整个参数空间
中找到损失函数的最小值。
迭代优化只能保证收敛到局部(邻域)最优解,而不是全局最优解。
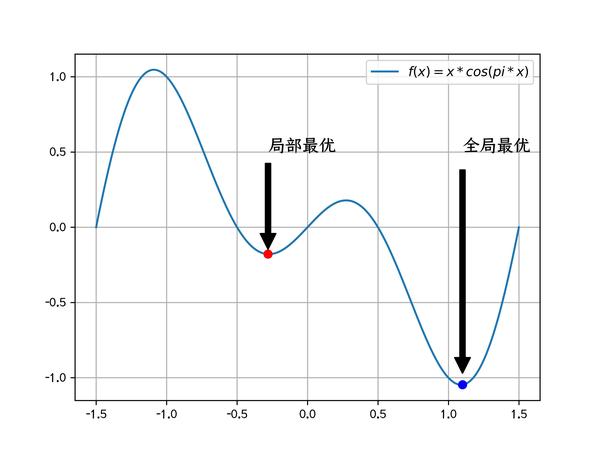
凸优化是一种定义在凸集和凸函数上的特殊的优化问题,能保证局部最优值=全局最优值。 简单来说凸集中的任意两点连线都在凸集内,凸函数任意两点的连线上的值都大于函数值。
凸优化的良好性质也限制了它的表达能力。其实只有两个模型满足凸优化
- 线性回归 线性回归的平方损失函数(二次函数)是典型的凸函数。
- Softmax回归 Softmax是交叉熵损失函数(但经过神经网络之后,再交叉熵就不具有凸性了)。
大多数现代深度学习模型并不是基于凸函数,主要的原因是它们所使用的激活函数往往是非凸的。
梯度下降是最简单的迭代求解算法。
每次迭代中,我们都沿着函数的负梯度方向(即最陡峭的下坡方向)进行一定距离的移动。
在大型数据集和深度学习模型中,我们通常使用小批量随机梯度下降。在此方法中,每次迭代选择的不是一个样本,而是一个包含多个样本的小批量。用小批量的梯度近似整体梯度,又可以充分利用并行计算能力,从而提高训练速度。
普通SGD迭代时,参数更新只和当前样本有关,容易陷入振荡不定的情况。通过引入“惯性”或“冲量” 这个概念,冲量法可以累积过去的梯度信息,从而使得迭代方向在连续步骤中更为稳定。
是一个超参数,它决定了冲量的“惯性”。在实际应用中,
通常设置为接近1的值,例如 0.9。
可以看到 是每个minibatch的指数级数
所以一般来说它移动得更快,因为它累加了历史梯度。通用的深度学习框架的SGD都内置了冲量参数。
Adagrad希望对每个参数分配个性化的学习率,对于出现频繁的特征(例如NLP中的高频词),Adagrad会降低其学习率,避免过度调整;对于稀疏的特征,Adagrad会增加其学习率。
Adagrad通过累积之前所有迭代中梯度的平方和来刻画特征的出现频率。如果一个特征在训练数据中经常出现,那么它的梯度会大,因此其累积的历史梯度也会增加。
是一个非常小的常数,防止除以零
对某一维度历史更新梯度量做惩罚,减少高频特征的学习率,增加低频特征的学习率,助力模型更好地跨越鞍点。
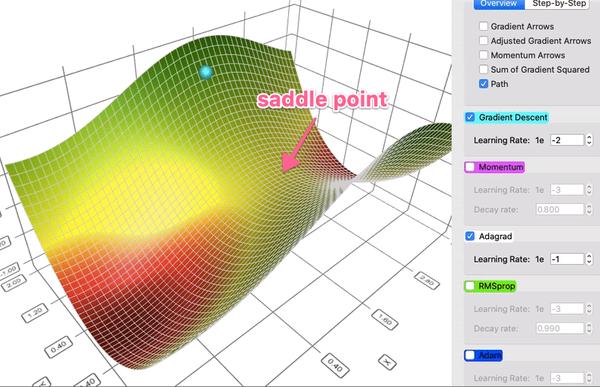
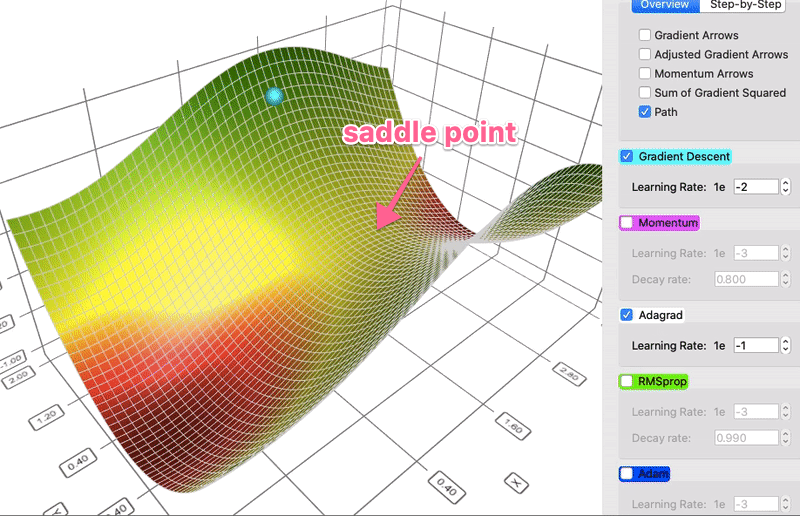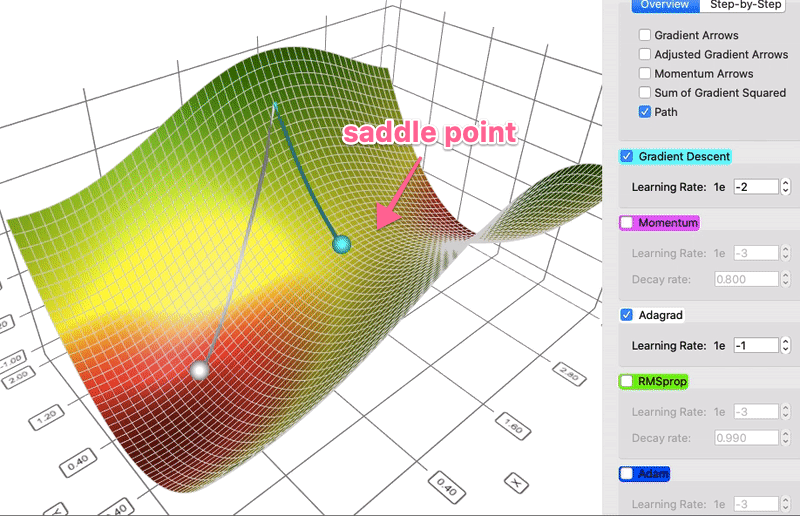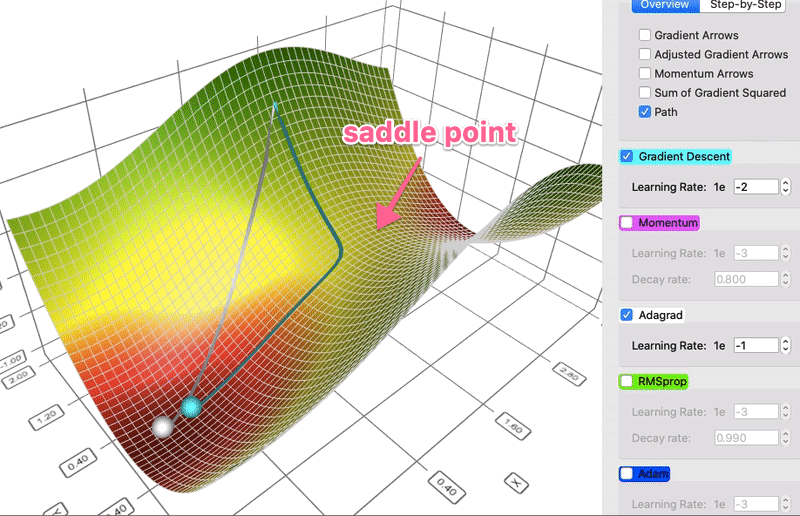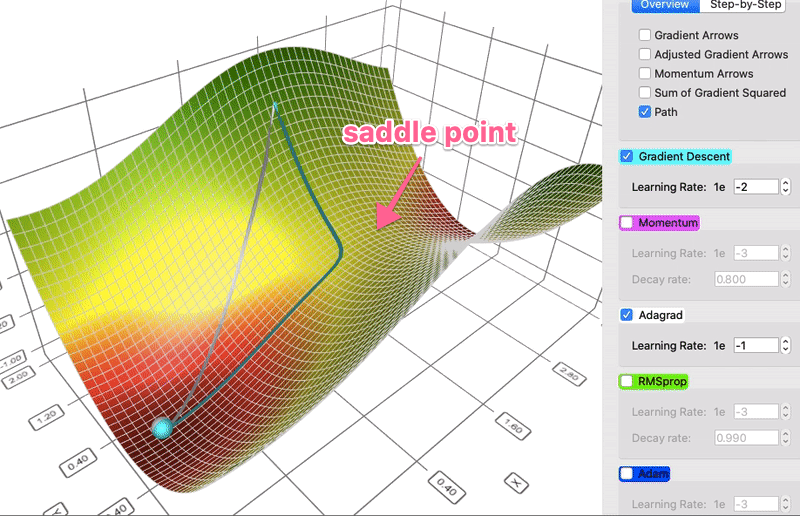
数据集较大时,Adagrad记录的梯度的平方和会越来越多,导致训练实际学习率过早衰减,训练很慢。 RMSProp 通过采用加权平均的方式来控制实际学习率的衰减程度。
是一个超参数,通常设置为接近 0.9 以上
Adam是现在最常用的优化器了,它综合了 Momentum 和 RMSProp 的优点,能够同时获得速度加速和自适应学习率的效果。
一阶动量(和Momentum相同)
通常 。
展开
可以证明所有 的权重之和为1
我们称RMSDrop的梯度平方和为二阶动量。
通常
初始化为0,而
很大(接近于1),导致初始的实际学习率太小。为了消除这种偏差,做出以下修正:
较小时,
。
本文使用 Zhihu On VSCode 创作并发布


