






任务简介:
学习最常用的优化器:torch.optim.SGD
详细说明:
深入了解学习率和momentum在梯度下降法中的作用,分析LR和Momentum这两个参数对优化过程的影响,最后学习optim.SGD以及pytorch的十种优化器简介。
梯度下降希望寻找函数的最小值,但可以看到y值不但没有减小,还越来越大了。
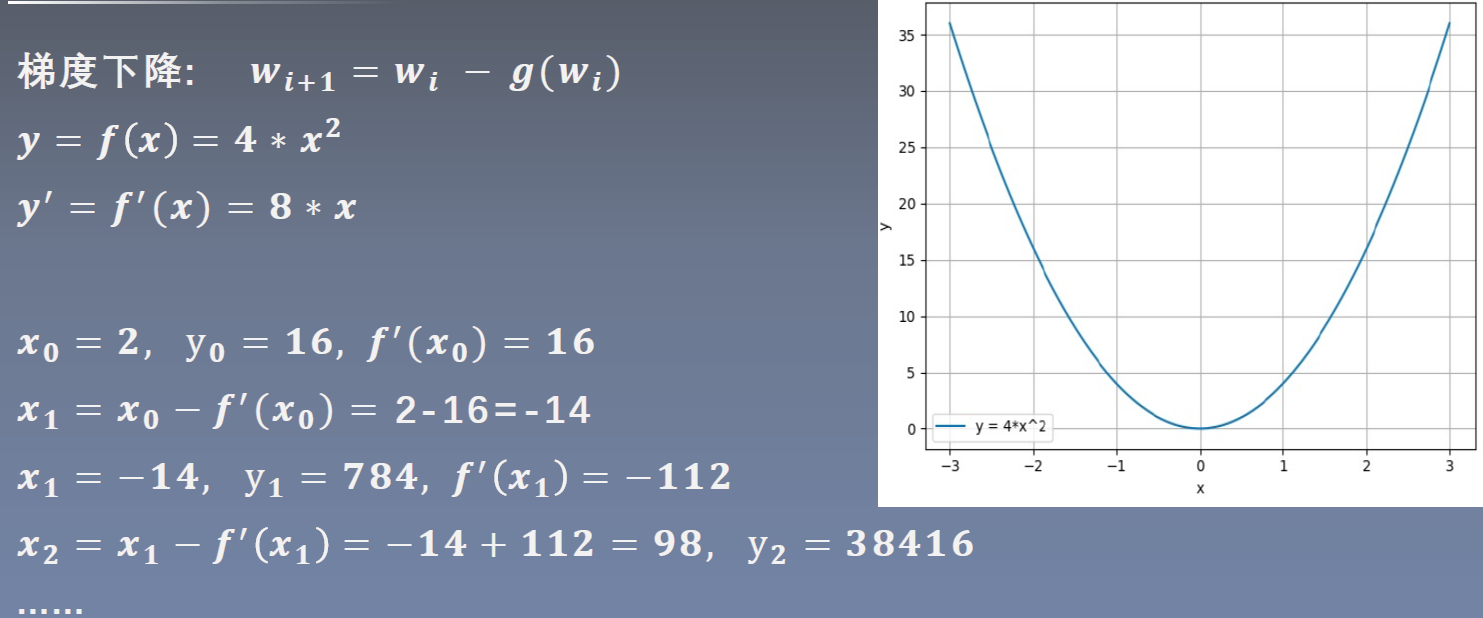
绘制函数图像:
输出:
测试梯度下降过程:
输出:
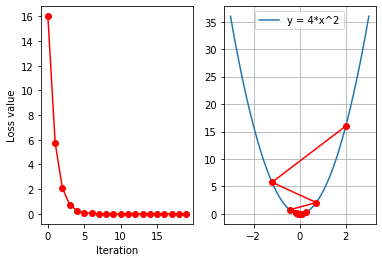
发生梯度爆炸
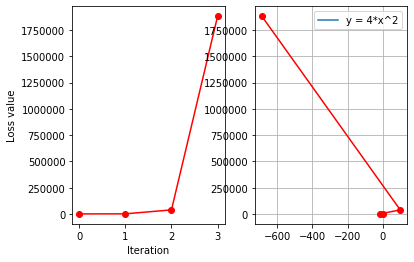
左边为loss曲线图,右边为梯度下降图像
为什么会出现梯度爆炸?
答: W i W_i Wi?减去的 g ( w i ) g(w_i) g(wi?)尺度太大,引起参数 W i + 1 W_{i+1} Wi+1?越来越大,导致函数值不能减小。
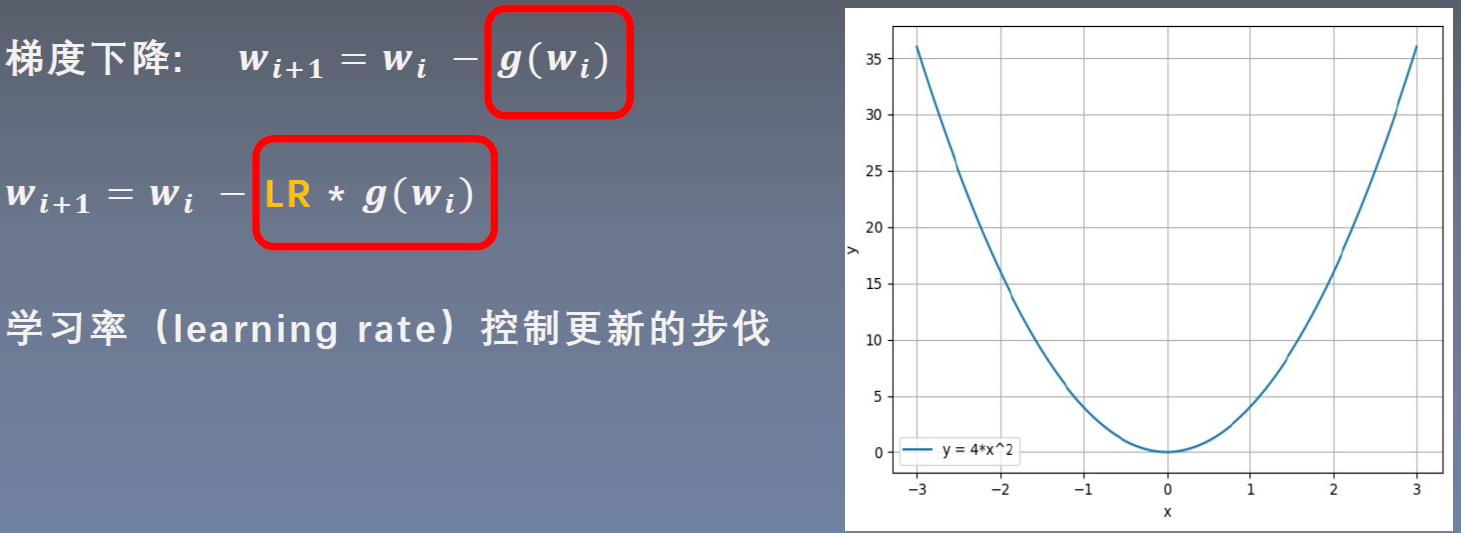
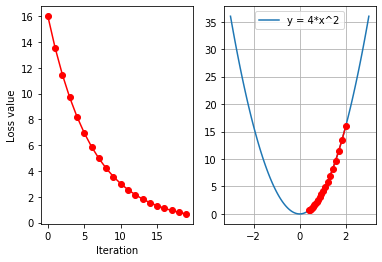
设置学习率:
迭代次数:
输出:
设置学习率:
输出:
测试多个学习率:
输出:
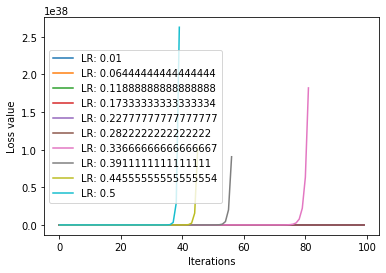
发现loss值有激增的情况。
减少最大学习率:
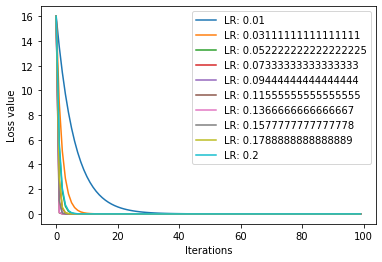
测试代码:
输出:
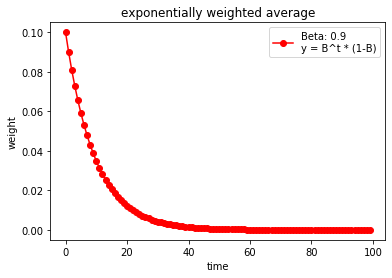
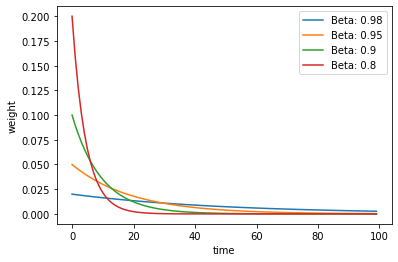
测试不同权重下的变化曲线:
输出:
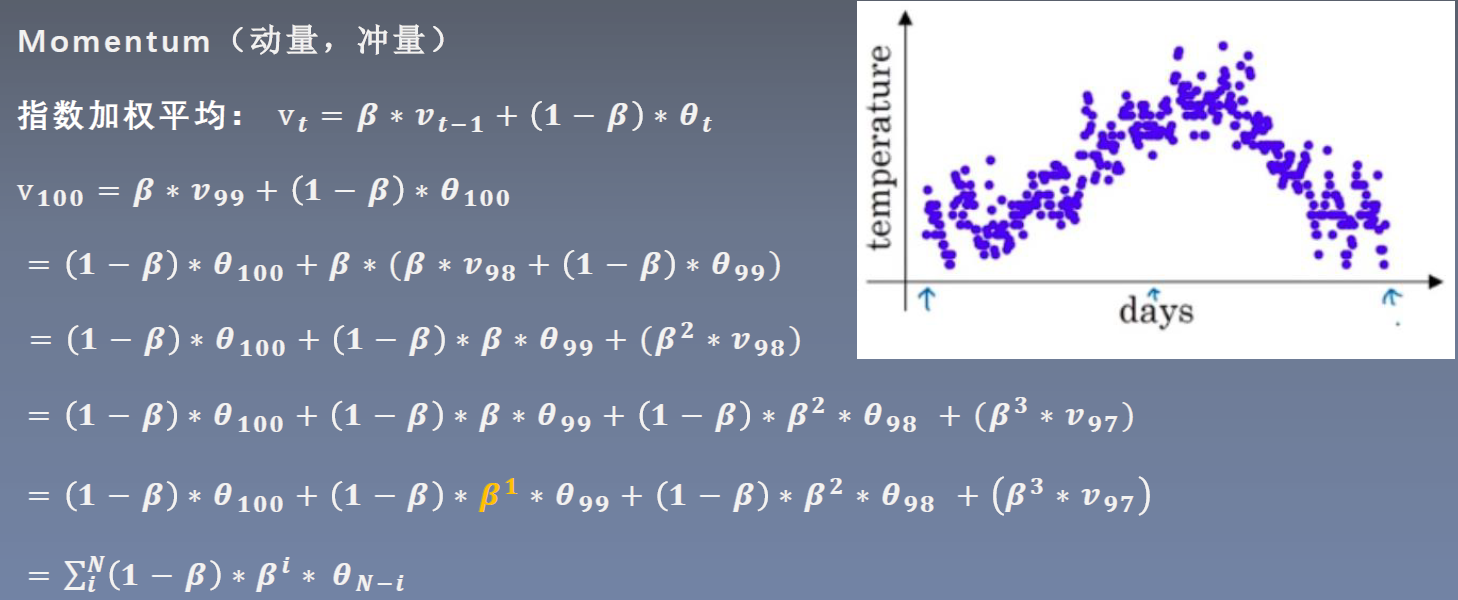
β
\beta
β 这个超参数是用来控制记忆周期,值越大记的越远。
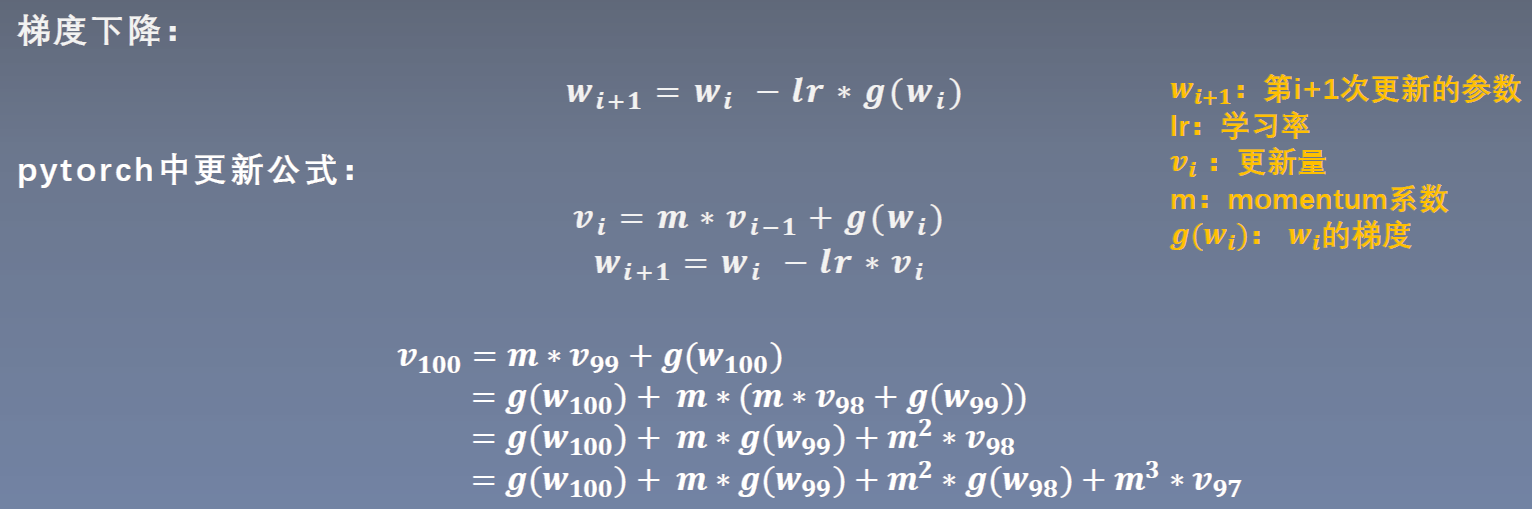
Momentum相关知识见《深度学习入门》P168。
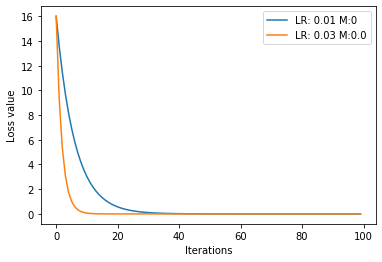
比较SGD和Momentum:
输出:
改变动量:
输出:
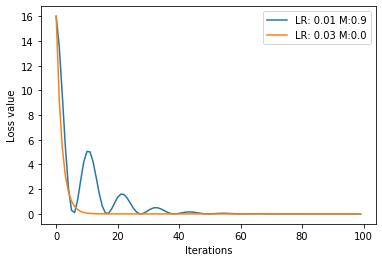
Momentum比SGD更快的达到了loss的较小值,但是由于权重过大,会受到前一时刻步长的影响,造成振荡。
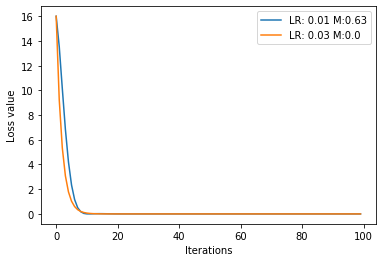
继续修改合适的值:
输出:


参考论文:



